Over the last few years, Platform Engineering has rapidly moved from a niche concept to a mainstream topic in modern IT conversations.
Unfortunately, it has also become one of the most misunderstood.
Depending on who you ask, Platform Engineering is described as:
- “DevOps with Kubernetes”
- A new CI/CD or internal tooling team
- A rebranding of SRE
- An internal PaaS you can buy or build
- Or simply “the team that owns the platform”
Most of these definitions are incomplete. Some are actively harmful. And that misunderstanding is one of the main reasons why so many platform initiatives fail.
Platform engineering is not a toolset
Let’s start by being explicit.
Platform Engineering is not:
- Kubernetes with a nicer interface
- A collection of CI/CD tools stitched together
- A vendor product you can purchase and install
- A support team with a new title
- A shortcut to organizational maturity
Tools are enablers, not the foundation.
Organizations that begin their platform journey by selecting tools almost always end up with:
- Increased complexity
- Higher cognitive load for engineers
- Fragmented ownership
- Low internal adoption
Because the underlying problem was never tooling.
Platform engineering is an operating model
At its core, Platform Engineering is an operating model.
It exists to solve a very concrete problem:
How do we enable teams to move fast without sacrificing reliability, security, and operational control?
The answer is not full decentralization. And it is not rigid centralization.
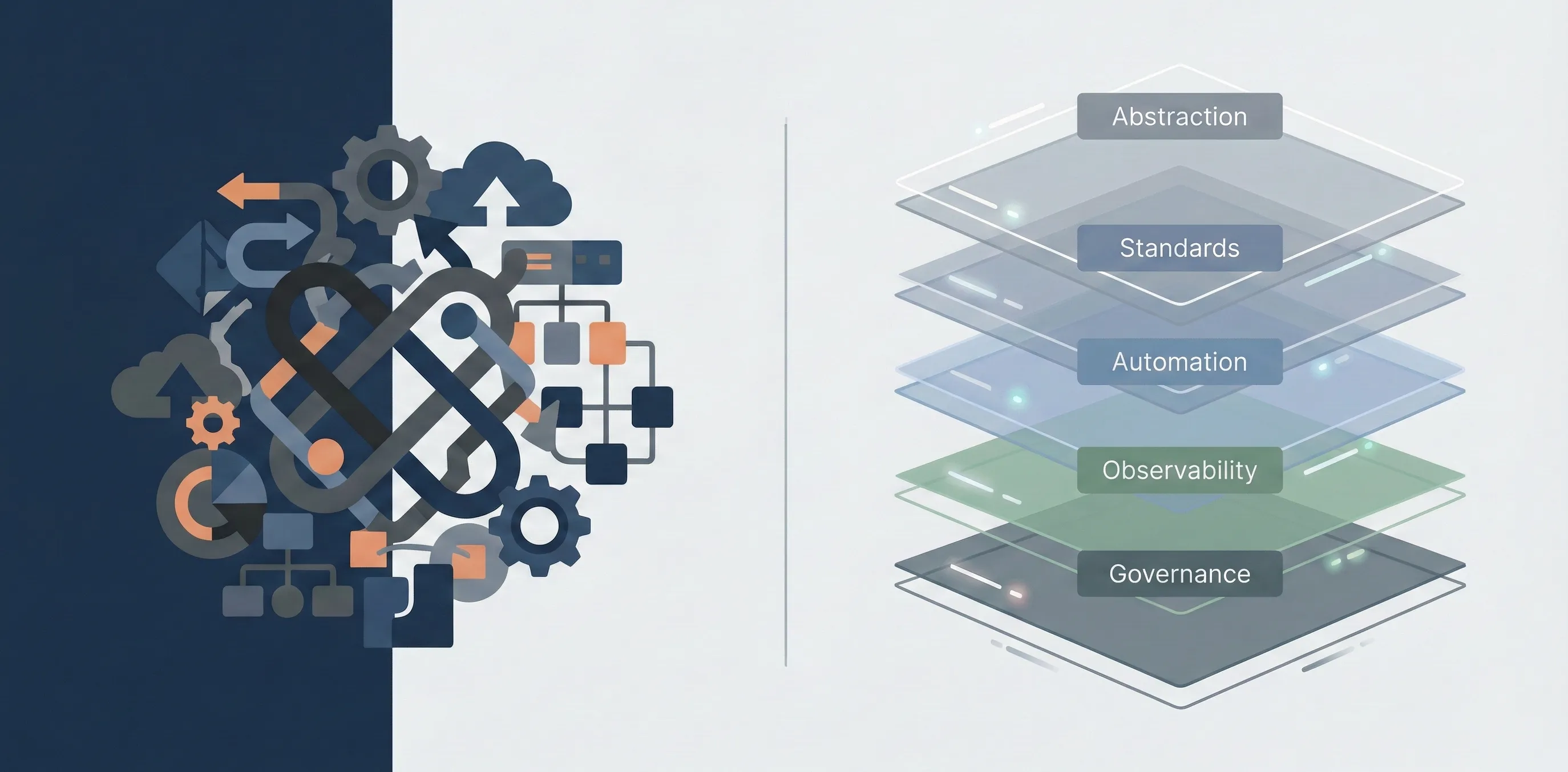
The answer is abstraction with accountability.
Platform Engineering defines:
- Clear boundaries
- Standardized paths
- Opinionated defaults
- Explicit ownership
All while preserving team autonomy.
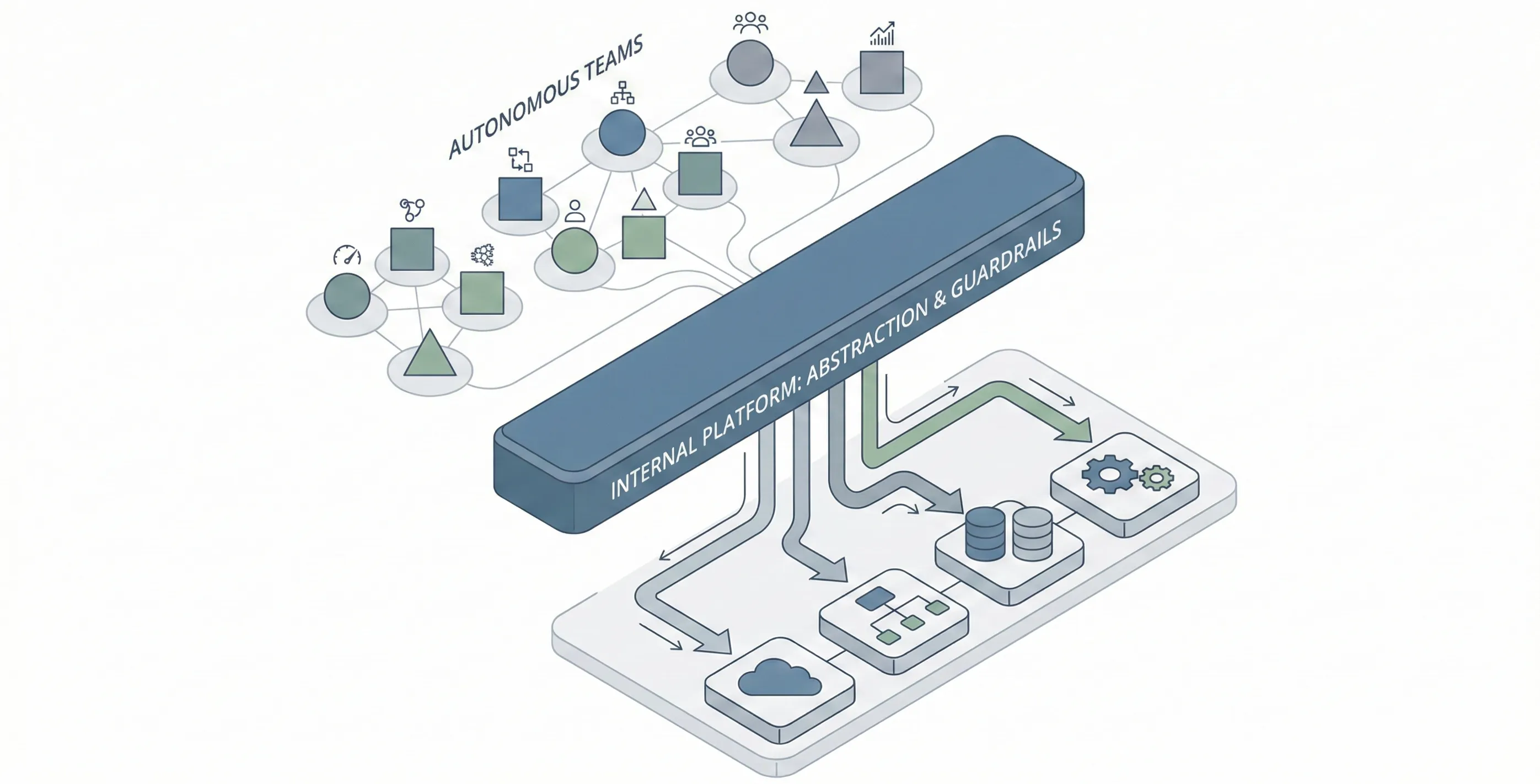
Internal platforms are products, not projects
A platform is not something you “deliver” and move on from.
A real internal platform:
- Has clearly defined users (developers, SREs, operators)
- Provides stable interfaces and contracts
- Optimizes for developer experience, not architecture diagrams
- Evolves based on feedback and adoption
- Is measured by usage, not feature count
Successful platform teams operate like product teams, not infrastructure teams.
If teams only use your platform because they are forced to, you do not have a platform. You have a mandate.
Hiding complexity without hiding responsibility
One of the most common misconceptions is that Platform Engineering is about “hiding complexity”.
It is - but only partially.
Good platforms:
- Hide implementation details
- Expose outcomes and constraints
- Make responsibility explicit
- Preserve operational awareness
Bad platforms:
- Create black boxes
- Obscure failure modes
- Shift responsibility without clarity
The goal is not ignorance. The goal is reduced cognitive load with clear ownership.
Platform engineering requires scale and complexity
Not every organization needs Platform Engineering.
If you have:
- Few teams
- Limited operational scope
- Low availability or compliance requirements
Introducing a platform team too early will likely slow you down.
Platform Engineering becomes necessary when:
- Teams multiply
- Environments diverge
- Knowledge becomes tribal
- Reliability depends on heroics
- Governance becomes manual and fragile
In short: when complexity becomes systemic.
Observability and operations are first-class citizens
A platform without observability is blind. A platform without operational workflows is incomplete.
Real platforms embed:
- Monitoring and observability by default
- Operational standards and guardrails
- Automated responses to known failure modes
- Clear escalation and ownership models
This is where Platform Engineering naturally converges with:
- SRE
- Observability
- Automation
- And eventually AIOps
Not as buzzwords - but as an evolution driven by operational reality.
Why most platform initiatives fail
Most platform initiatives fail for predictable reasons:
- They are tool-driven instead of problem-driven
- They optimize for architecture over experience
- They lack long-term ownership and executive alignment
- They try to solve everything at once
- They ignore day-to-day operations
Platform Engineering is not a transformation you “finish”. It is a continuous discipline.
Platform engineering is engineering applied to operations

At its best, Platform Engineering is simply this:
Engineering principles applied to operational reality.
It is about:
- Making the right path the easy path
- Encoding best practices into platforms
- Reducing cognitive load at scale
- Enabling autonomy without chaos
No hype. No shortcuts. Just disciplined engineering.
